
“Talk is cheap. Show me the code.”
Linus Torvalds

For the last 2 years while working at ISD, I’ve been involved in the development of different features for our customers and various bug fixes. The most challenging tasks that I managed to polish up were related to the ORM framework that we use.
In this article I’ll try to answer some basic questions such as, “Do I need to use an ORM in my application?”, “What is Object Relational Mapping and JPA?”, “What is the difference between JPA and Hibernate or EclipseLink?”.
Object-relational mapping
According to the official documentation an ORM “is a programming technique for converting data between incompatible type systems using object-oriented programming languages. This creates, in effect, a “virtual object database” that can be used from within the programming language”. In other words, the object-relational mapping is the concept of linking object-oriented data with a data store, by mapping them.
Before going into details I’ll try to answer the most important question of this article: “Do I need to use an ORM in my application?”. There is no predefined answer to this question, you have to decide for yourself, but before making the decision, you should clearly understand the purpose of the application, the architectural constraints and last but not least, the knowledge base you possess and the desire of learning something new. Below are some advantages and disadvantages, which might help you making the right decision:
Advantages:
- Focus more on business logic and less on data storage;
- Less and more readable code;
- Easier to persist and retrieve data to/from data storage.
Disadvantages:
- An ORM decreases the application startup. You first need to create the entities, annotate them, configure ORM properties, and only then you will be able to read and persist data;
- ORMs are slow when it comes to executing some complex queries. Before retrieving some data, the ORM first has to generate the SQL queries, and if there are lots of relations between entities, the time for creating and executing the query can be significant.
Java Persistence API
Java Persistence API (JPA) is part of Java Enterprise Edition 5, a set of interfaces meant to greatly simplify Java persistence and to provide an object-relational mapping approach that lets the developer declaratively define how to map Java objects to relational database tables in a standard or portable way.
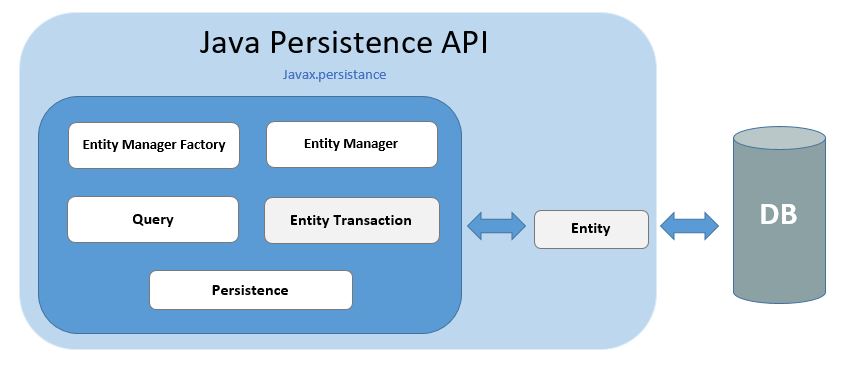
Let’s now see a bit of more details about these interfaces and try to understand how they work:
- Persistence – this is a class actually, which contains three static methods, two for obtaining the EntityManagerFactory and one for getting PersistenceUtil interface;
- EntityManagerFactory – an interface, which has the scope of creating/maintaining EntityManager instances;
- EntityManager – an interface, meant to manage all the operations performed on an entity. It also creates and maintains Query instances;
- EntityTransaction – an interface which manages the transactions;
- Query – an interface, used to control the query execution;
- Entity – persistence objects, stored as records in the database.
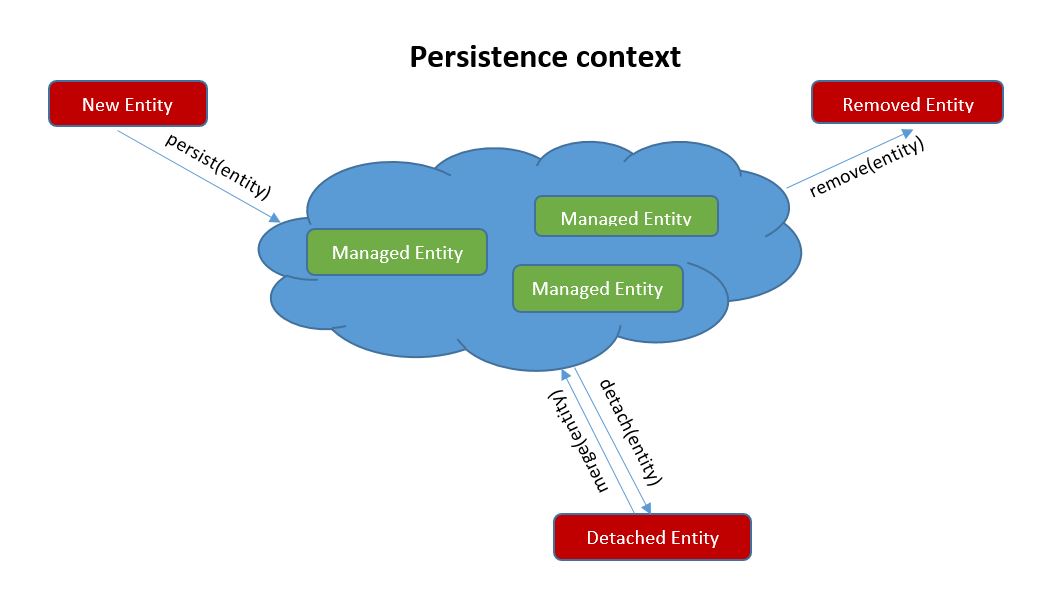
When an EntityManager is created via createEntityManager method, a persistence-context is instantiated. An EntityManager is associated with a persistence-context. The persistence-context is a set of managed unique entity instances. Therefore, it handles a set of entities, which will be persisted in the data store.
An entity can be in one of four states as defined below:
- New (Transient) – when the entity was just created and not persisted yet;
- Persistent (Managed) – after the entity was persisted (method
persist); - Detached – an entity which is no longer associated with a persistent context (method
detach); - Removed – an entity that was deleted from the persistence context and database (method
remove).
Let’s now analyze an example where I tried to show the amount and complexity of the code to simply read some data from database with and without an ORM.
Getting data without JPA:
[code language=”java” firstline=”0″]
public class FindStockKeepableUsingJDBC {
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection(DB_URL, USER, PASS);
stmt = conn.createStatement();
String sql = "SELECT id, capacity FROM wms_stockkeepable where id = ‘Location01’";
ResultSet rs = stmt.executeQuery(sql);
while (rs.next()) {
//Retrieve by column name
String id = rs.getString("id");
int capacity = rs.getInt("capacity");
System.out.print("Id: " + id);
System.out.print(", Capacity: “+ capacity);
}
} catch (SQLException se) {
se.printStackTrace();
} finally {
rs.close();
stmt.close();
conn.close();
}
}
}
}
[/code]
Getting data with JPA:
First of all, we have to create an object model – our Entity and add the required annotations.
[code language=”java” firstline=”0″]
@Entity
@Table(name = "WMS_STOCKKEEPABLE")
public class StockKeepable {
@Id
protected String id;
@Column(name = "CAPACITY")
private Long capacity;
public StockKeepable(String id, Long capacity) {
this.id = id;
this.capacity = capacity;
}
@Override
public String getId() {
return id;
}
@Override
public void setId(String id) {
this.id = id;
}
@Override
public Long getCapacity() {
return capacity;
}
@Override
public void setCapacity(Long capacity) {
this.capacity = capacity;
}
}
[/code]
Here are some important annotations defined by JPA:
- @Entity – specifies that the class is a JPA entity and will be mapped to a database table;
- @Table – used to declare the table name;
- @Basic – non persistent column;
- @Embedded – specify that the property or entity is instance of an embedded class;
- @Id – primary key of an entity/table;
- @Transient – specifies the column which doesn’t have to be stored in the database;
- @Column – specifies a table column;
- @AccessType – specifies how to access mapped properties of an entity, either using the getters and setters to read/set values on a field, or bypassing them and accessing the field directly;
- @UniqueConstraint – adds a constraint on a table column to ensure values uniqueness;
- @ManyToMany, @ManyToOne, @OneToMany, @OneToOne – relationships between tables;
- @NamedQueries, @NamedQuery – static defined query/queries with a predefined query string.
Once the model is ready, we can proceed to the next step and try to get an object from database by ID.
[code language=”java” firstline=”0″]
public class FindStockKeepable {
public static void main(String[] args) {
EntityManagerFactory entityManagerFactory = Persistance.createEntityManagerFactory("persistence-test");
EntityManager entityManager = entityManagerFactory.createEntityManager();
StockKeepable sk = entityManager.find(StockKeepable.class, "Location01");
System.out.print("Logical Id: " + sk.getId());
System.out.print(", Capacity: " + sk.getCapacity());
entityManager.close();
}
}
[/code]
Let me explain what I did here. So, as you remember, the EntityManagerFactory is responsible for managing the EntityManagers. When creating an EntityManagerFactory we need to pass as a parameter the name of the persistenceUnit, which in our case is “persistence-test”. But what is a persistenceUnit?, you might ask. A persistence unit defines a logical group of entity classes managed by EntityManagers. It is possible to configure more than one persistence unit. They are defined Inside persistence.xml file – the central piece of configuration.
Examplaining persistence.xml
[code language=”xml” firstline=”0″]
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="https://java.sun.com/xml/ns/persistence" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="https://java.sun.com/xml/ns/persistence https://java.sun.com/xml/ns/persistence/persistence_2_0.xsd" version="2.0">
<persistence-unit name="persistence-test" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.driver" value="org.hsqldb.jdbcDriver" />
<property name="javax.persistence.jdbc.url" value="jdbc:hsqldb:mem:standalone-test" />
<property name="javax.persistence.jdbc.user" value="inther" />
<property name="javax.persistence.jdbc.password" value="" />
</properties>
</persistence-unit>
</persistence>
[/code]
A persistence unit defines several properties, most basic being the data source driver, data source name, the user and the password to connect to the database.
Once we have an EntityManagerFactory, we can create the EntityManger, that would be our “magic wand” with the help of which we will be able to manipulate data. The most important operations that an EntityManger can do are as follows:
- Persist an entity (method
persist); - Find objects from data source (method
find); - Synchronize persistence context state with database state (method
flush); - Create Query instances (method
createQuery); - Get EntityTransaction (method
getTransaction).
Let’s now have a look at another example where I will try to persist a newly created entity:
[code language=”java” firstline=”0″]
public class CreateStockKeepable {
public static void main(String[] args) {
EntityManagerFactory entityManagerFactory = Persistance.createEntityManagerFactory("persistence – test");
EntityManager entityManager = entityManagerFactory.createEntityManager();
entityManager.getTransaction().begin();
//Create a new StockKeepable
StockKeepable sk = new StockKeepable("Location02", 3000 l)
entityManager.persist(sk);
entityManager.getTransaction.commit();
entityManager.close();
entityManagerFactory.close();
}
}
[/code]
In order to commit our changes to the data storage, we first need to open a transaction. Calling the persist(sk) method on our entityManager makes the entity persistent, however doesn’t yet write it to the database. To do so, we need to commit the transaction. A transaction can be rolled back, which will cancel the effect produced by the persist method, basically will remove the entity.
You may have noticed that in the end, we call the close() methods on entityManager and entityManagerFactory. EnityManagerFactory is a heavyweight object, so it’s better to create just one instance and keep it for more time rather than repeatedly create and close it. By closing it, the associated resources will be removed – the EntityManager pool, the connection pool, the cache.
Unlike EnityManagerFactory, EntityManager could be created more often, even every time you want to write or access data, yet make sure to close each instance when it is not needed anymore, otherwise it won’t release the resources it uses.
It’s worth mentioning that JPA defines just a set of interfaces, to use it you need a specific provider. Most popular are Hibernate, Toplink, EclipseLink, Apache OpenJPA, DataNucleus, ObjectDB, CMobileCom JPA. Every provider has its own advantages and disadvantages, therefore it’s up to you to choose which one better fits your application.
The database is the key part of any application, using an ORM you will slow down the whole development and implementation process of the application, but it’s a trade-off worth taking. It’s simple to use it, all what needs to be done, is to annotate entities and use JPA tools for accessing and persisting data. Your application structure will become more flexible, thus being ready to switch the provider whenever it is required, the application becomes more scalable, being more responsive to changes and last but not least the code gets to be more readable.
The conclusion is as simple as it gets, don’t hesitate to use an ORM!
References: